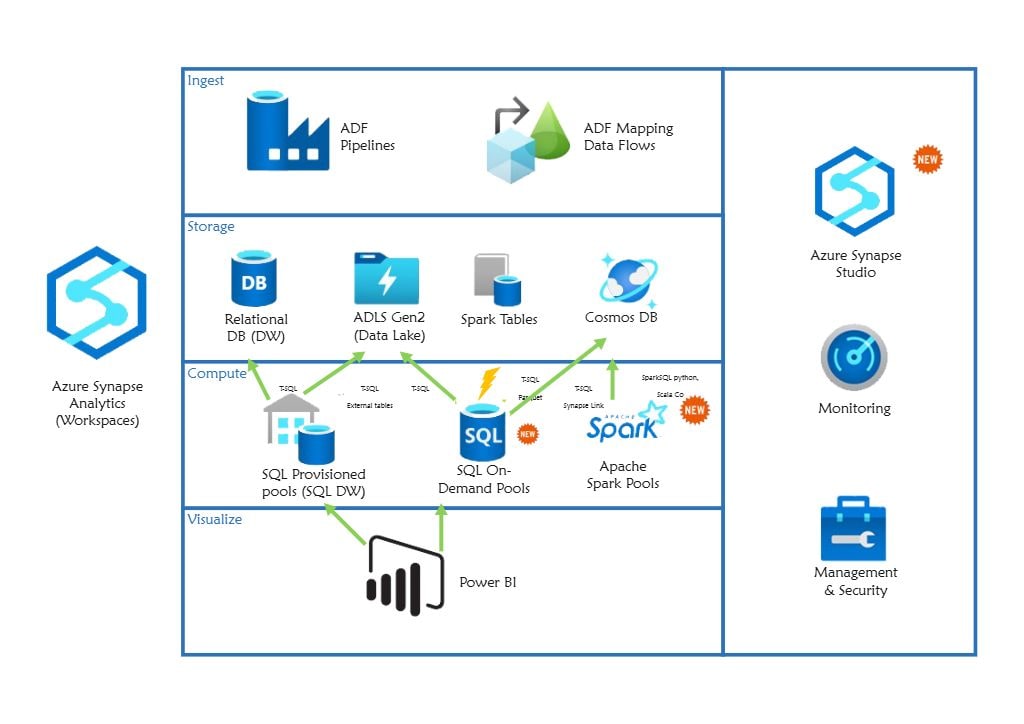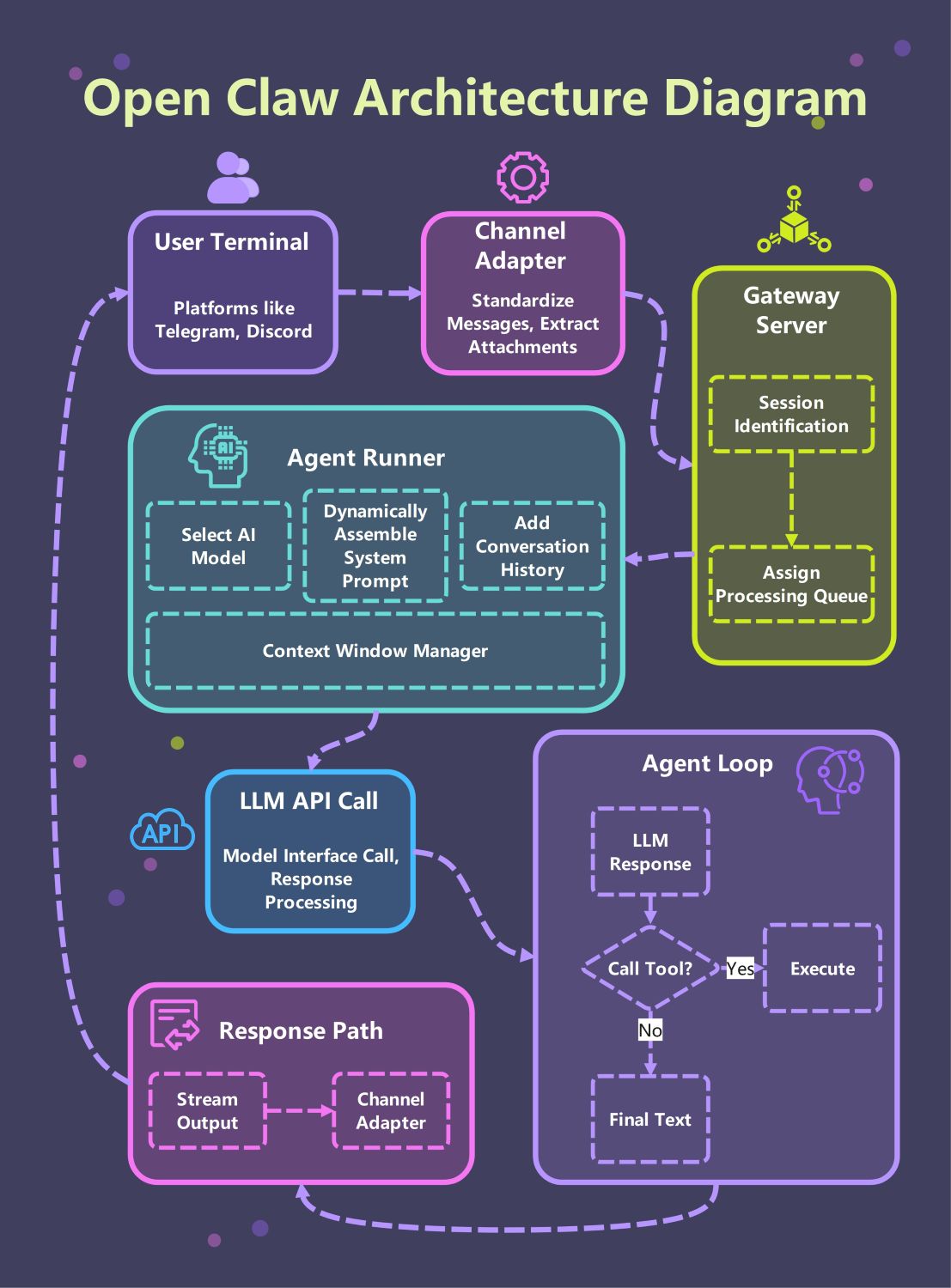
Informazioni su questo diagramma dell'architettura Open Claw
Questo modello fornisce una guida visiva completa al sistema Open Claw. Evidenzia il percorso critico dai terminali utente attraverso il gateway fino al ciclo dell'agente principale, rendendo più facile comprendere come i componenti AI modulari interagiscono in un ambiente professionale.
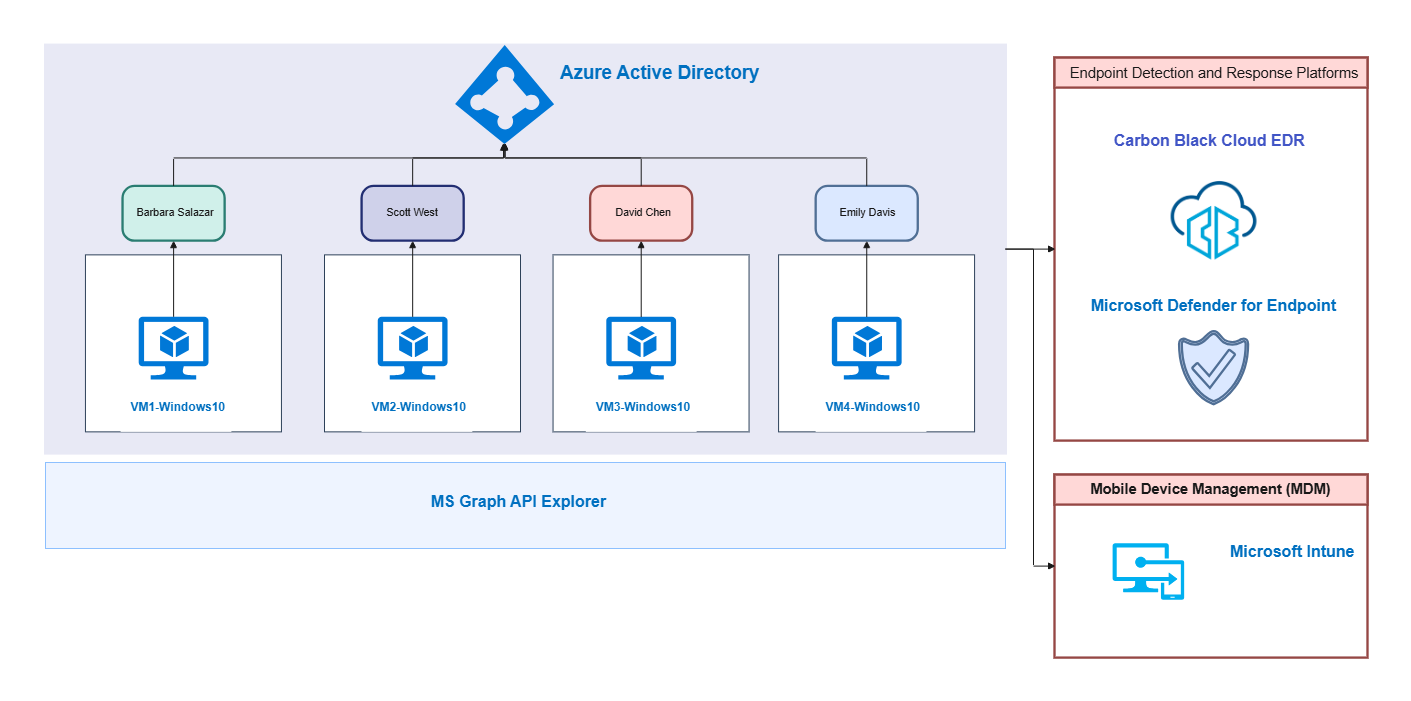
Terminale utente e adattatore di canale
Il sistema inizia dal terminale utente, dove le persone interagiscono tramite piattaforme come Telegram o Discord. L'adattatore di canale standardizza quindi questi messaggi in arrivo ed estrae eventuali allegati rilevanti per un'ulteriore elaborazione.
- Integrazione Telegram e Discord
- Standardizzazione dei messaggi
- Estrazione degli allegati
- Supporto multipiattaforma
Livello server gateway
Il server gateway funge da controllore di traffico principale per l'intera architettura. Esegue l'identificazione della sessione per mantenere lo stato dell'utente e assegna le richieste alle code di elaborazione per garantire prestazioni fluide ed equilibrate.
- Identificazione della sessione
- Assegnazione della coda di elaborazione
- Gestione del traffico
- Instradamento delle richieste
Nucleo dell'Agent Runner
L'agent runner è il cuore del sistema dove avviene l'assemblaggio dei prompt. Seleziona il modello AI appropriato, aggiunge la cronologia delle conversazioni e utilizza un gestore della finestra di contesto per mantenere i dati entro i limiti dei token.
- Selezione del modello AI
- Assemblaggio dinamico dei prompt
- Tracciamento della cronologia delle conversazioni
- Gestione della finestra di contesto
Chiamata API LLM e ciclo dell'agente
L'agente entra in un ciclo iterativo in cui comunica con l'LLM. Elabora le risposte e decide se eseguire uno strumento o fornire il testo finale, assicurando che le azioni siano fondate su risultati in tempo reale.
- Chiamate all'interfaccia del modello
- Elaborazione delle risposte
- Logica di esecuzione degli strumenti
- Ciclo di ragionamento iterativo
Percorso di risposta e output
Una volta che l'agente completa il suo ragionamento, il percorso di risposta gestisce la consegna. L'output viene trasmesso in streaming attraverso l'adattatore di canale, garantendo che l'utente riceva il testo finale istantaneamente sulla piattaforma di chat scelta.
- Output in streaming
- Generazione del testo finale
- Formattazione specifica del canale
- Feedback utente in tempo reale
FAQ su questo template
-
Qual è il ruolo principale del Gateway Server in questa architettura?
Il Gateway Server funge da controllore del traffico per l'intera architettura. Esegue l'identificazione della sessione per tenere traccia dei singoli utenti e delle loro interazioni specifiche. Inoltre, assegna le richieste alle code di elaborazione per bilanciare il carico del sistema. Questo garantisce che gli agenti AI gestiscano più richieste in modo fluido senza mandare in crash il server o perdere dati importanti.
-
Come gestisce l'Agent Runner il contesto della conversazione?
L'Agent Runner funziona come una catena di montaggio per l'intelligenza dell'AI. Seleziona il modello AI appropriato e costruisce dinamicamente i prompt di sistema unendo cronologia e istruzioni. Inoltre, il Context Window Manager previene l'overflow dei dati monitorando il conteggio dei token e attivando la sintesi quando necessario. Questo garantisce che l'agente rimanga concentrato e coerente durante lunghe conversazioni senza perdere importanti dettagli dell'utente.
-
Cosa accade durante il processo di Agent Loop?
L'Agent Loop è un processo iterativo in cui l'AI decide come rispondere. Se l'LLM identifica un'attività che richiede dati esterni, attiva una chiamata allo strumento per l'esecuzione. Una volta che lo strumento fornisce un risultato, il ciclo riparte per elaborare le nuove informazioni. Questo ciclo si ripete fino a quando il modello genera il testo finale, garantendo che ogni risposta sia fondata su azioni del mondo reale.