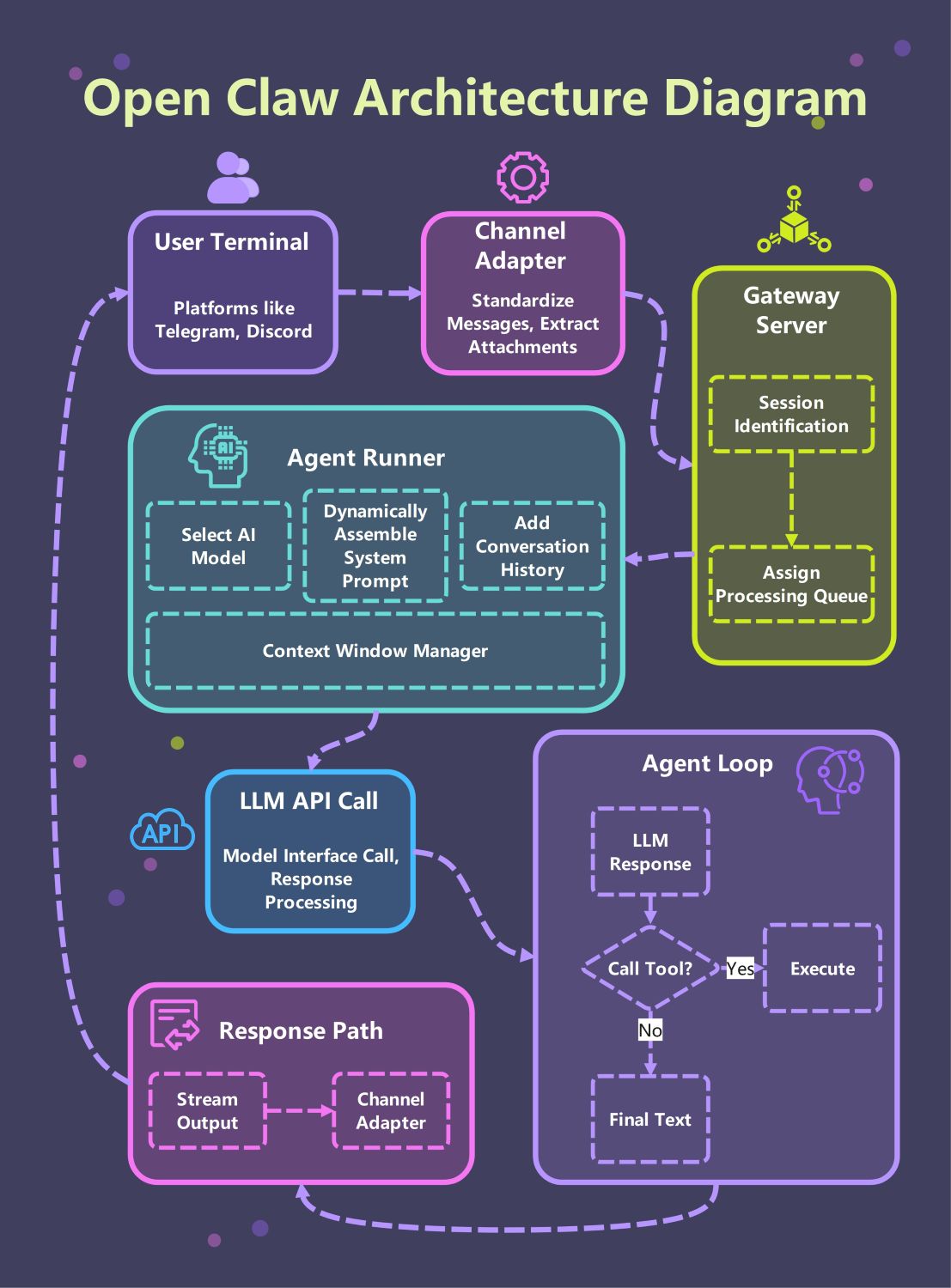
À propos de ce modèle d'architecture Open Claw
Ce modèle offre un guide visuel complet du système Open Claw. Il met en évidence le chemin critique depuis les terminaux utilisateur via la passerelle jusqu'à la boucle principale de l'agent, facilitant la compréhension de l'interaction des composants IA modulaires dans un environnement professionnel.
Terminal Utilisateur et Adaptateur de Canal
Le système commence au terminal utilisateur, où l'on interagit par des plateformes comme Telegram ou Discord. L'adaptateur de canal standardise ensuite ces messages entrants et extrait les pièces jointes pertinentes pour un traitement ultérieur.
- Intégration Telegram et Discord
- Standardisation des messages
- Extraction des pièces jointes
- Support multiplateforme
Couche du Serveur Passerelle
Le serveur passerelle agit comme le contrôleur principal du trafic sur toute l'architecture. Il effectue l'identification des sessions pour conserver l'état de l'utilisateur et attribue les requêtes à des files de traitement afin de garantir des performances fluides et équilibrées.
- Identification de session
- Attribution aux files de traitement
- Gestion du trafic
- Routage des requêtes
Noyau Agent Runner
L'Agent Runner est le cœur du système où l'assemblage des prompts se déroule. Il sélectionne le modèle IA adapté, ajoute l'historique de conversation, et utilise un gestionnaire de fenêtre de contexte pour respecter les limites de tokens.
- Sélection du modèle IA
- Assemblage dynamique des prompts
- Suivi de l'historique des conversations
- Gestion des fenêtres de contexte
Appel API LLM et Boucle de l'Agent
L'agent entre dans une boucle itérative où il communique avec le LLM. Il traite les réponses et décide d'exécuter un outil ou de fournir le texte final, garantissant que les actions sont fondées sur des résultats en temps réel.
- Appels d'interface de modèle
- Traitement des réponses
- Logique d'exécution d'outil
- Cycle de raisonnement itératif
Chemin de réponse et sortie
Une fois le raisonnement de l'agent terminé, le chemin de réponse gère la livraison. La sortie est retransmise via l'adaptateur de canal, garantissant que l'utilisateur reçoit instantanément le texte final sur sa plateforme de chat choisie.
- Sortie en streaming
- Génération du texte final
- Formatage spécifique au canal
- Retour utilisateur en temps réel
FAQ concernant ce modèle
-
Quel est le rôle principal du serveur passerelle dans cette architecture ?
Le serveur passerelle agit comme le contrôleur du trafic pour l'ensemble de l'architecture. Il effectue l'identification de session pour suivre les utilisateurs individuels et leurs interactions spécifiques. De plus, il assigne les requêtes aux files d'attente de traitement afin d'équilibrer la charge du système. Cela garantit que les agents IA traitent plusieurs demandes en douceur sans faire planter le serveur ni perdre de données importantes.
-
Comment le gestionnaire d'agents gère-t-il le contexte de la conversation ?
Le gestionnaire d'agents fonctionne comme une chaîne de montage pour l'intelligence de l'IA. Il sélectionne le modèle d'IA approprié et construit dynamiquement les prompts système en fusionnant l'historique et les instructions. De plus, le gestionnaire de fenêtre de contexte prévient la surcharge de données en surveillant le nombre de jetons et en déclenchant un résumé si nécessaire. Cela permet à l'agent de rester concentré et cohérent tout au long de longues conversations sans perdre de détails importants sur l'utilisateur.
-
Que se passe-t-il lors du processus de la boucle d'agent ?
La boucle d'agent est un processus itératif où l'IA décide comment répondre. Si le LLM identifie une tâche nécessitant des données externes, il déclenche l'appel d'un outil pour l'exécution. Une fois que l'outil fournit un résultat, la boucle recommence pour traiter cette nouvelle information. Ce cycle se répète jusqu'à ce que le modèle génère le texte final, garantissant que chaque réponse est basée sur des actions réelles.



