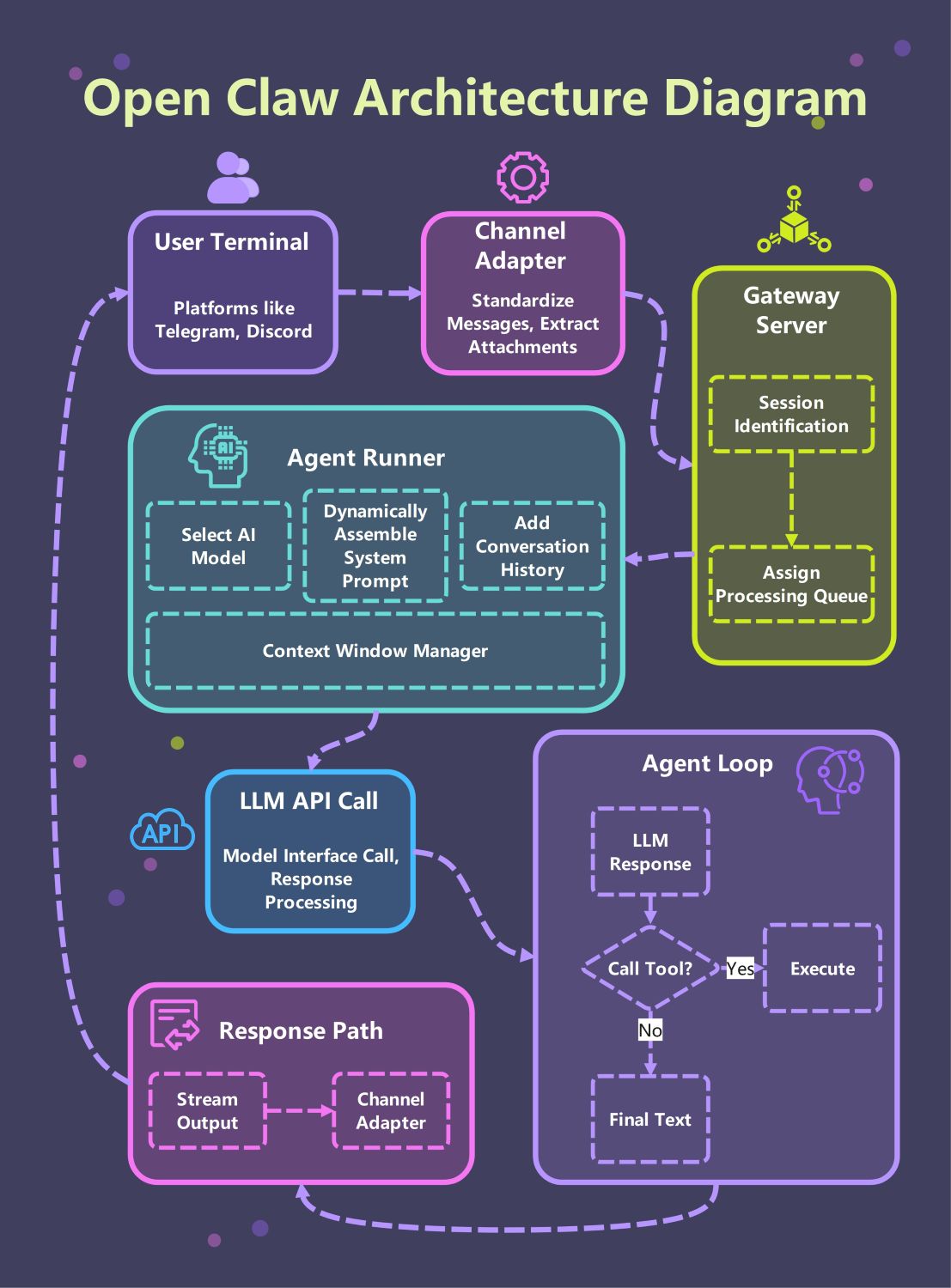
Über dieses Open Claw Architekturdiagramm
Diese Vorlage bietet eine umfassende visuelle Übersicht über das Open Claw System. Sie hebt den kritischen Pfad von Nutzerterminals über das Gateway bis zur zentralen Agent-Loop hervor und erleichtert das Verständnis, wie modulare KI-Komponenten in einer professionellen Umgebung zusammenwirken.
Nutzerterminal und Kanaladapter
Das System beginnt am Nutzerterminal, wo Personen über Plattformen wie Telegram oder Discord interagieren. Der Kanaladapter standardisiert anschließend diese eingehenden Nachrichten und extrahiert alle relevanten Anhänge zur weiteren Verarbeitung.
- Telegram- und Discord-Integration
- Nachrichtenstandardisierung
- Anhang-Extraktion
- Multi-Plattform-Unterstützung
Gateway-Server-Ebene
Der Gateway-Server fungiert als zentrale Verkehrssteuerung für die gesamte Architektur. Er führt eine Sitzungsidentifikation durch, um den Nutzerstatus aufrechtzuerhalten, und weist Anfragen Verarbeitungswarteschlangen zu, um eine reibungslose und ausgewogene Performance zu gewährleisten.
- Sitzungsidentifikation
- Zuweisung von Verarbeitungswarteschlangen
- Traffic-Management
- Anfragen-Routing
Agent Runner Kern
Der Agent Runner ist das Herzstück des Systems, in dem die Prompt-Zusammenstellung erfolgt. Er wählt das geeignete KI-Modell aus, fügt den Gesprächsverlauf hinzu und nutzt einen Kontextfenster-Manager, um die Daten innerhalb der Token-Limits zu halten.
- KI-Modell-Auswahl
- Dynamische Prompt-Zusammenstellung
- Gesprächsverlaufs-Tracking
- Kontextfenster-Management
LLM-API-Aufruf und Agent-Loop
Der Agent tritt in eine iterative Schleife ein, in der er mit dem LLM kommuniziert. Er verarbeitet Antworten und entscheidet, ob ein Tool ausgeführt oder finaler Text bereitgestellt werden soll, wobei sichergestellt wird, dass Aktionen auf Echtzeit-Ergebnissen basieren.
- Modellschnittstellen-Aufrufe
- Antwortverarbeitung
- Tool-Ausführungslogik
- Iterativer Reasoning-Zyklus
Antwortpfad und Ausgabe
Sobald der Agent seine Verarbeitung abgeschlossen hat, übernimmt der Antwortpfad die Zustellung. Die Ausgabe wird über den Kanaladapter zurückgestreamt, sodass der Nutzer den finalen Text sofort auf seiner gewählten Chat-Plattform erhält.
- Streaming-Ausgabe
- Finale Textgenerierung
- Kanalspezifische Formatierung
- Echtzeit-Nutzerfeedback
FAQs zu dieser Vorlage
-
Welche Hauptaufgabe hat der Gateway-Server in dieser Architektur?
Der Gateway-Server fungiert als Verkehrskontrollpunkt für die gesamte Architektur. Er führt eine Sitzungserkennung durch, um einzelne Nutzer und deren spezifische Interaktionen zu verfolgen. Außerdem weist er Anfragen Verarbeitungswarteschlangen zu, um die Systemlast auszugleichen. Dies gewährleistet, dass die KI-Agenten mehrere Anfragen reibungslos verarbeiten, ohne dass der Server abstürzt oder wichtige Daten verloren gehen.
-
Wie verwaltet der Agent Runner den Gesprächskontext?
Der Agent Runner funktioniert wie ein Fließband für die Intelligenz der KI. Er wählt das passende KI-Modell aus und erstellt dynamisch System-Prompts, indem er Verlauf und Anweisungen zusammenführt. Zusätzlich verhindert der Context Window Manager Datenüberläufe, indem er Token-Anzahlen überwacht und bei Bedarf eine Zusammenfassung auslöst. So bleibt der Agent während langer Gespräche fokussiert und kohärent, ohne wichtige Nutzerdetails zu verlieren.
-
Was geschieht während des Agent-Loop-Prozesses?
Der Agent Loop ist ein iterativer Prozess, bei dem die KI entscheidet, wie sie reagieren soll. Wenn das LLM eine Aufgabe erkennt, die externe Daten erfordert, löst es einen Tool-Aufruf zur Ausführung aus. Sobald das Tool ein Ergebnis liefert, startet der Loop neu, um die neuen Informationen zu verarbeiten. Dieser Zyklus wiederholt sich, bis das Modell den finalen Text generiert, wodurch sichergestellt wird, dass jede Antwort auf realen Aktionen basiert.