Comunidad de plantillas /
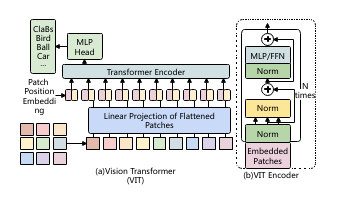
VIT (Vision Transformer) and VIT Encoder
VIT (Vision Transformer) and VIT Encoder
Isabelmia
Publicado el 2024-11-26
Generar diagrama con IA
Plantilla
Escritorio
Vision Transformer (VIT) and VIT Encoder are important components of the deep learning model. They process input data through a series of neural network layers and use the self-attention mechanism to capture
Compartir
Añadir comentario
Publicar
Close
Close


 Escritorio
Escritorio